
Únase a nosotros el 30 de abril: Presentación de la prueba CT de Parasoft C/C++ para pruebas continuas y excelencia en el cumplimiento | Regístrese ahora
Saltar a la sección
Cómo prevenir el desbordamiento del búfer y otros errores de administración de la memoria

28 de noviembre.
10 min leer
Cuando el volumen de datos excede la capacidad de almacenamiento del búfer de memoria, experimenta un desbordamiento del búfer. Vea cómo la función de verificación de análisis estático en la solución Parasoft C/C++ puede ayudarlo a administrar los errores de los desbordamientos del búfer.
Saltar a la sección
Saltar a la sección
La gestión de la memoria está plagada de peligros, especialmente en C y C++. De hecho, los errores asociados con las debilidades de la gestión de la memoria constituyen una parte considerable del CWE Top 25. Ocho de los 25 principales están directamente relacionados con desbordamiento de búfer, punteros deficientes y gestión de la memoria.
La principal debilidad del software por un amplio margen es CWE-119, "Restricción incorrecta de operaciones dentro de los límites de un búfer de memoria". Estos tipos de errores ocupan un lugar destacado en los problemas de seguridad y protección en todo tipo de software, incluidas las aplicaciones críticas para la seguridad en automóviles, dispositivos médicos y aviónica.
Estos son los errores de memoria relacionados con enumeraciones de debilidades comunes del CWE Top 25:
| Rango | ID | Nombre |
|---|---|---|
| [ 1 ] | CWE-787 | Escritura fuera de límites |
| [ 4 ] | CWE-416 | Usar después gratis |
| [ 7 ] | CWE-125 | Fuera de límites Leer |
| [ 12 ] | CWE-476 | Desreferencia del puntero NULO |
| [ 14 ] | CWE-190 | Desbordamiento de enteros o envolvente |
| [ 17 ] | CWE-119 | Restricción inadecuada de operaciones dentro de los límites de un búfer de memoria |
Aunque estos errores han afectado a C, C ++ y otros lenguajes durante décadas, todavía ocurren con un número creciente en la actualidad. Son errores peligrosos en términos de consecuencias para la calidad, la seguridad y la confiabilidad, y su presencia es una de las principales causas de las vulnerabilidades de seguridad.
¿Qué son los desbordamientos de búfer?
Un desbordamiento del búfer ocurre cuando se escriben más datos en una parte de la memoria o búfer de los que puede contener, por ejemplo, si intenta colocar 12 letras en un cuadro que solo contiene 10. Esto puede provocar la sobrescritura de la memoria adyacente. espacios, provocando un comportamiento impredecible en un programa.
Los errores de desbordamiento del búfer pueden afectar significativamente tanto a la calidad como a la seguridad y la confiabilidad del software. Desde una perspectiva de seguridad, los actores malintencionados pueden aprovechar los errores de desbordamiento del búfer para ejecutar código arbitrario o interrumpir las operaciones de un sistema. Esto se debe a que cuando se produce un desbordamiento del búfer, un atacante puede controlar qué datos se escriben más allá del búfer, lo que podría permitirle alterar el flujo de ejecución del programa.
Por lo tanto, es crucial que los desarrolladores implementen un manejo sólido de datos y prueben adecuadamente su software para evitar desbordamiento de búfer errores y mantener la integridad y seguridad de su software.
Causa principal de vulnerabilidades de seguridad
Microsoft descubierto CRISPR que durante los últimos 12 años, más del 70% de las vulnerabilidades de seguridad en sus productos se debieron a problemas de seguridad de la memoria. Este tipo de errores son la mayor superficie de ataque para su aplicación y los piratas informáticos los están utilizando. Según su investigación, las principales causas de los ataques a la seguridad fueron el uso fuera de los límites, el uso después de la liberación y el uso no inicializado. Como señalan, las clases de vulnerabilidad existen desde hace 20 años o más y todavía prevalecen en la actualidad.
De manera similar, Google descubrió que el 70% de las vulnerabilidades de seguridad en el proyecto Chromium, la base de código abierto para el navegador Chrome, se deben a estos mismos problemas de gestión de memoria. Su principal causa también fue el uso después de la liberación, mientras que otras formas de gestión de memoria inseguras ocuparon el segundo lugar.
Dados estos ejemplos de hallazgos del mundo real, es fundamental que los equipos de software tomen en serio este tipo de errores. Afortunadamente, existen formas de prevenir y detectar este tipo de problemas con un análisis estático que es efectivo y eficiente.
Cómo los errores de administración de memoria se convierten en vulnerabilidades de seguridad
En la mayoría de los casos, los errores de gestión de la memoria son el resultado de prácticas de programación deficientes con el uso de punteros en C / C ++ y el acceso a la memoria directamente. En otros casos, está relacionado con hacer suposiciones erróneas sobre la longitud y el contenido de los datos.
Estas debilidades del software se explotan con mayor frecuencia con datos contaminados, datos externos a la aplicación cuya longitud o formato no se ha verificado. El infame heartbleed La vulnerabilidad es un caso de explotación de un desbordamiento de búfer. Técnicamente, es una lectura excesiva del búfer. Como comentamos en nuestro blog anterior sobre Inyecciones SQL, el uso de entradas que no están controladas ni restringidas es un riesgo para la seguridad.
Consideremos algunas de las principales categorías de debilidades del software de administración de memoria. El principal es CWE-119: Restricción inadecuada de operaciones dentro de los límites de un búfer de memoria.
Desbordamiento de búfer
Lenguajes de programación, generalmente C y C++, que permiten el acceso directo a la memoria y no verifican automáticamente que las ubicaciones a las que se accede sean válidas y propensas a errores de corrupción de memoria. Esta corrupción puede ocurrir en áreas de datos y código de la memoria, lo que puede exponer información confidencial, provocar la ejecución de código no deseada o provocar que una aplicación falle.
El siguiente ejemplo muestra un caso clásico de desbordamiento de búfer de CWE-120:
char last_name[20];
printf ("Enter your last name: ");
scanf ("%s", last_name);En este caso, no hay restricción en la entrada del usuario desde scanf () sin embargo, el límite en la longitud de apellido tiene 20 caracteres. Ingresar un apellido de más de 20 caracteres termina copiando la entrada del usuario en la memoria más allá de los límites del búfer apellido. Aquí hay un ejemplo más sutil de CWE-119:
void host_lookup(char *user_supplied_addr){
struct hostent *hp;
in_addr_t *addr;
char hostname[64];
in_addr_t inet_addr(const char *cp);
/*routine that ensures user_supplied_addr is in the right format for conversion */
validate_addr_form(user_supplied_addr);
addr = inet_addr(user_supplied_addr);
hp = gethostbyaddr( addr, sizeof(struct in_addr), AF_INET);
strcpy(hostname, hp->h_name);
}Esta función toma una cadena proporcionada por el usuario que contiene una dirección IP, por ejemplo, 127.0.0.1, y recupera su nombre de host.
La función valida la entrada del usuario (¡bien!) Pero no verifica la salida de gethostbyaddr () (¡Mal!) En este caso, un nombre de host largo es suficiente para desbordar el búfer de nombre de host que actualmente está limitado a 64 caracteres. Tenga en cuenta que si gethostaddr () devuelve un valor nulo cuando no se puede encontrar un nombre de host, ¡también hay un error de desreferencia del puntero nulo!
Errores de uso después de la liberación
Curiosamente, Microsoft, en su estudio, observó que los errores de uso después de la liberación eran los problemas de administración de memoria más comunes que enfrentaban. Como su nombre lo indica, el error se relaciona con el uso de punteros en el caso de C/C++ que acceden a la memoria previamente liberada. C y C++ generalmente dependen del desarrollador para administrar la asignación de memoria, lo que a menudo puede ser complicado de hacer de manera completamente correcta. Como muestra el siguiente ejemplo de CWE-416, a menudo es fácil asumir que un puntero sigue siendo válido:
char* ptr = (char*)malloc (SIZE);
if (err) {
abrt = 1;
free(ptr);
}
...
if (abrt) {
logError("operation aborted before commit", ptr);
}En el ejemplo anterior, el puntero ptr es libre si un error es verdadero, pero luego se desreferencia más tarde, después de ser liberado, si resumen es verdadero, que se establece en verdadero si equivocarse es verdad. Esto puede parecer artificial, pero si hay mucho código entre estos dos fragmentos de código, es fácil pasarlo por alto. Además, esto sólo podría ocurrir en una condición de error que no se prueba adecuadamente.
Desreferencia del puntero NULO
Otra debilidad común del software es el uso de punteros u objetos en C++ y Java que se espera que sean válidos pero que son NULL. Aunque estas desreferencias se consideran excepciones en lenguajes como Java, pueden provocar que una aplicación se detenga, se cierre o se bloquee. Tomemos el siguiente ejemplo, en Java, de CWE-476:
String cmd = System.getProperty("cmd");
cmd = cmd.trim();Esto parece inofensivo ya que el desarrollador podría suponer que el getProperty () El método siempre devuelve algo. De hecho, si la propiedad "Cmd" no existe, se devuelve un NULL causando una excepción de desreferencia NULL cuando se usa. Aunque esto suene benigno, puede llevar a resultados desastrosos.
En raras circunstancias, cuando NULL es equivalente a la dirección de memoria 0x0 y el código privilegiado puede acceder a ella, es posible escribir o leer la memoria, lo que puede llevar a la ejecución del código.
Estrategias de mitigación efectivas
Hay varias mitigaciones disponibles que los desarrolladores deben implementar. Principalmente, los desarrolladores deben asegurarse de que los punteros sean válidos para lenguajes como C y C ++ con lógica verificada y verificación exhaustiva.
Para todos los lenguajes, es imperativo que cualquier código o biblioteca que manipule la memoria valide los parámetros de entrada para evitar el acceso fuera de los límites. A continuación se muestran algunas opciones de mitigación que están disponibles. Pero los desarrolladores no deberían confiar en ellos para compensar las malas prácticas de programación.
Elección del lenguaje de programación
Algunos lenguajes proporcionan protección integrada contra desbordamientos como Ada y C #.
Uso de bibliotecas seguras
Está disponible el uso de bibliotecas, como Safe C String Library, que proporcionan comprobaciones integradas para evitar errores de memoria. Sin embargo, no todos los desbordamientos de búfer son el resultado de la manipulación de cadenas. Salvo esto, los programadores siempre deben recurrir a funciones que toman la longitud de los búferes como argumentos, por ejemplo, strncpy () strcpy ().
Endurecimiento de compilación y tiempo de ejecución
Este enfoque hace uso de opciones de compilación que agregan código a la aplicación para monitorear los usos del puntero. Este código agregado puede evitar que se produzcan errores de desbordamiento en tiempo de ejecución.
Endurecimiento del entorno de ejecución
Los sistemas operativos tienen opciones para evitar la ejecución de código en áreas de datos de una aplicación, como un desbordamiento de pila con inyección de código. También hay opciones para organizar aleatoriamente la asignación de memoria para evitar que los piratas informáticos predigan dónde puede residir el código explotable.
A pesar de estas mitigaciones, no hay reemplazo para las prácticas de codificación adecuadas para evitar desbordamientos de búfer en primer lugar. Por lo tanto, la detección y la prevención son fundamentales para reducir los riesgos de estas debilidades del software.
Cambiar la detección y eliminación de desbordamientos de búfer
Adoptar un enfoque DevSecOps para el desarrollo de software significa integrar la seguridad en todos los aspectos de la canalización de DevOps. Así como los procesos de calidad como el análisis de código y las pruebas unitarias se impulsan lo antes posible en SDLC, lo mismo es cierto para la seguridad.
Los desbordamientos de búfer y otros errores de administración de memoria podrían ser cosa del pasado si los equipos de desarrollo adoptaran un enfoque de este tipo de manera más amplia. Como muestra la investigación de Google y Microsoft, estos errores aún representan el 70% de sus vulnerabilidades de seguridad. Independientemente, describamos un enfoque que los previene lo antes posible.
Encontrar y corregir errores en la administración de memoria vale la pena en comparación con parchear una aplicación lanzada. El enfoque de detección y prevención que se describe a continuación se basa en trasladar la mitigación de los desbordamientos de búfer a las primeras etapas de desarrollo. Y reforzando esto con la detección a través del análisis de código estático.
Detección
La detección de errores de administración de memoria se basa en un análisis estático para encontrar este tipo de vulnerabilidades en el código fuente. La detección ocurre en el escritorio del desarrollador y en el sistema de compilación. Puede incluir código existente, heredado y de terceros.
La detección de problemas de seguridad de forma continua garantiza la búsqueda de cualquier problema que:
- Los desarrolladores se perdieron en el IDE.
- Existen en un código anterior a su nuevo enfoque de detección y prevención.
El enfoque recomendado es un modelo de confianza pero verificación. El análisis de seguridad se realiza a nivel de IDE, donde los desarrolladores toman decisiones en tiempo real en función de los informes que obtienen. A continuación, verifique en el nivel de compilación. Idealmente, el objetivo a nivel de compilación no es encontrar vulnerabilidades. Es para verificar que el sistema esté limpio.
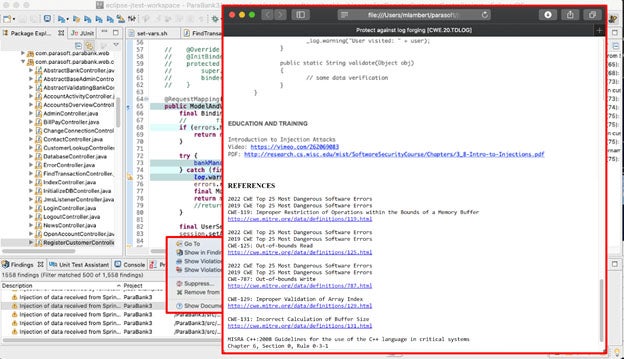
Parasoft C / C ++test incluye verificadores de análisis estático para este tipo de errores de gestión de memoria, incluidos los desbordamientos de búfer. Considere el siguiente ejemplo tomado de la prueba C / C ++.
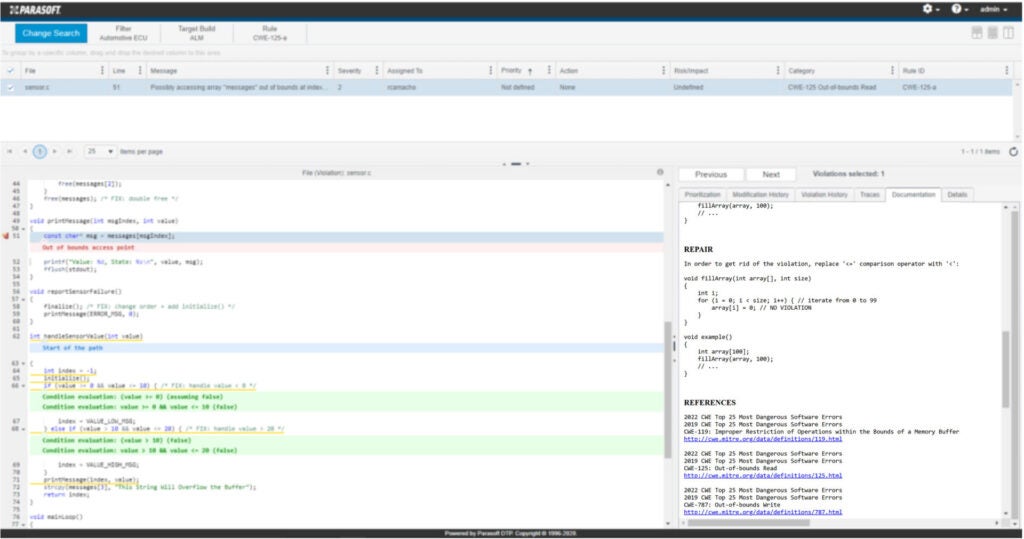
Acercándonos a los detalles, la función printMessage () error detecta el error:
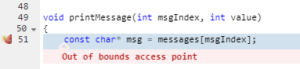
La prueba de Parasoft C / C ++ también proporciona información de seguimiento sobre cómo llegó la herramienta a esta advertencia:
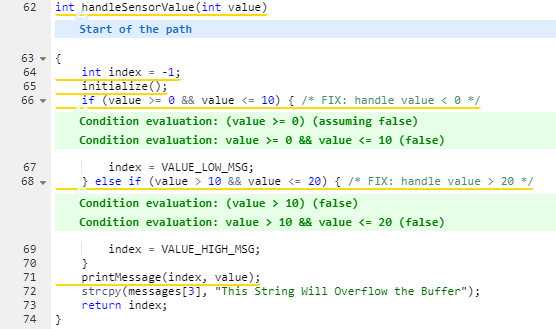
La barra lateral muestra detalles sobre cómo reparar esta vulnerabilidad junto con las referencias apropiadas:
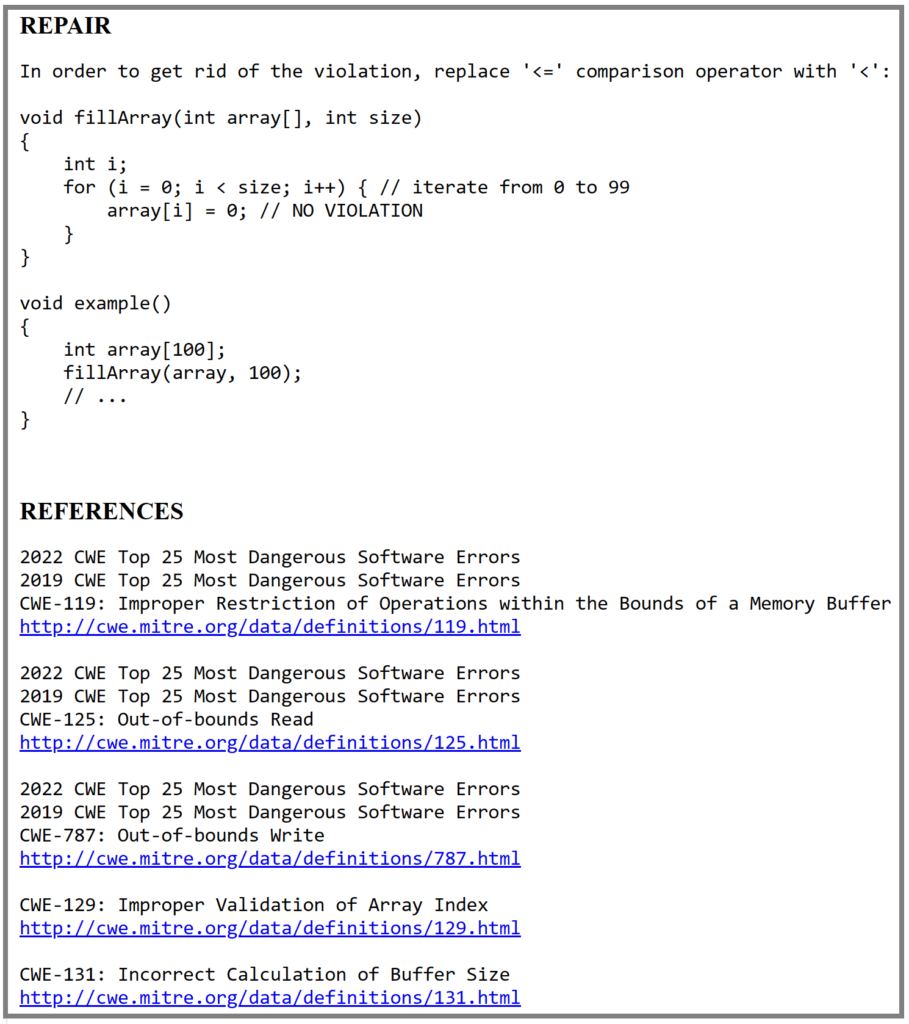
La detección precisa, junto con la información de apoyo y las recomendaciones de corrección, son fundamentales para que el análisis estático y la detección temprana de estas vulnerabilidades sean útiles y procesables de inmediato para los desarrolladores.
Prevención de desbordamientos de búfer y otros errores de administración de memoria
El momento y el lugar ideales para evitar desbordamientos de búfer es cuando los desarrolladores escriben código en su IDE. Los equipos que están adoptando estándares de codificación segura como SEI CERT C para C y C ++ y OWASP Top 10 para Java y .NET o CWE Top 25, todos tienen pautas que advierten sobre errores de administración de memoria.
Por ejemplo, CERT C incluye las siguientes reglas para la gestión de la memoria:

Estas reglas incluyen técnicas de codificación preventiva que evitan errores de gestión de la memoria en primer lugar. Cada conjunto de reglas incluye una evaluación de riesgos junto con los costos de remediación, lo que permite a los equipos de software priorizar las pautas de la siguiente manera:
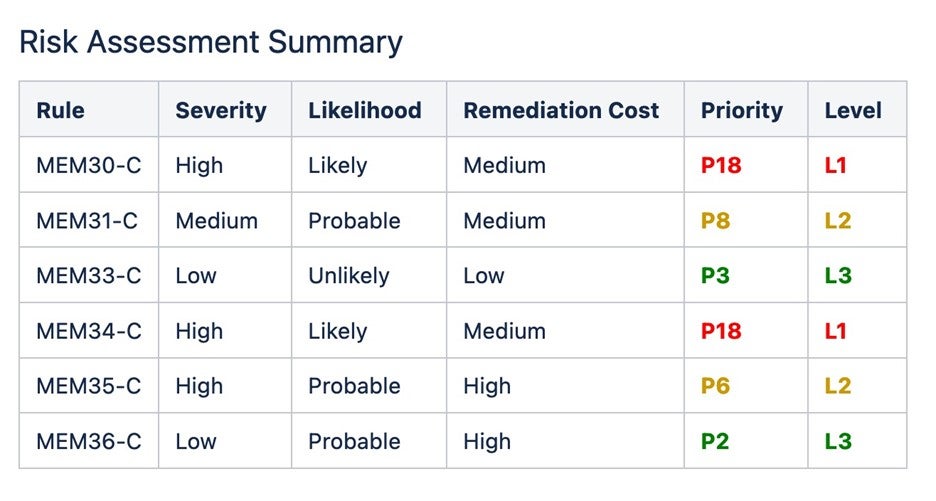
En el uso de la palabra regla en el CERT C, es más probable que violar una regla cause un defecto, y el cumplimiento debe realizarse de forma automática o manual mediante la inspección del código. Las reglas se consideran obligatorias. Cualquier excepción hecha por violaciones de las reglas debe documentarse.
Por otro lado, una recomendación proporciona una guía que, cuando se sigue, debería mejorar la seguridad y la confiabilidad. Sin embargo, una violación de una recomendación no necesariamente indica la presencia de un defecto en el código. Las recomendaciones no son obligatorias.
CERT C tiene las siguientes recomendaciones para la gestión de memoria:

La evaluación de riesgos asociada es la siguiente para estas recomendaciones:
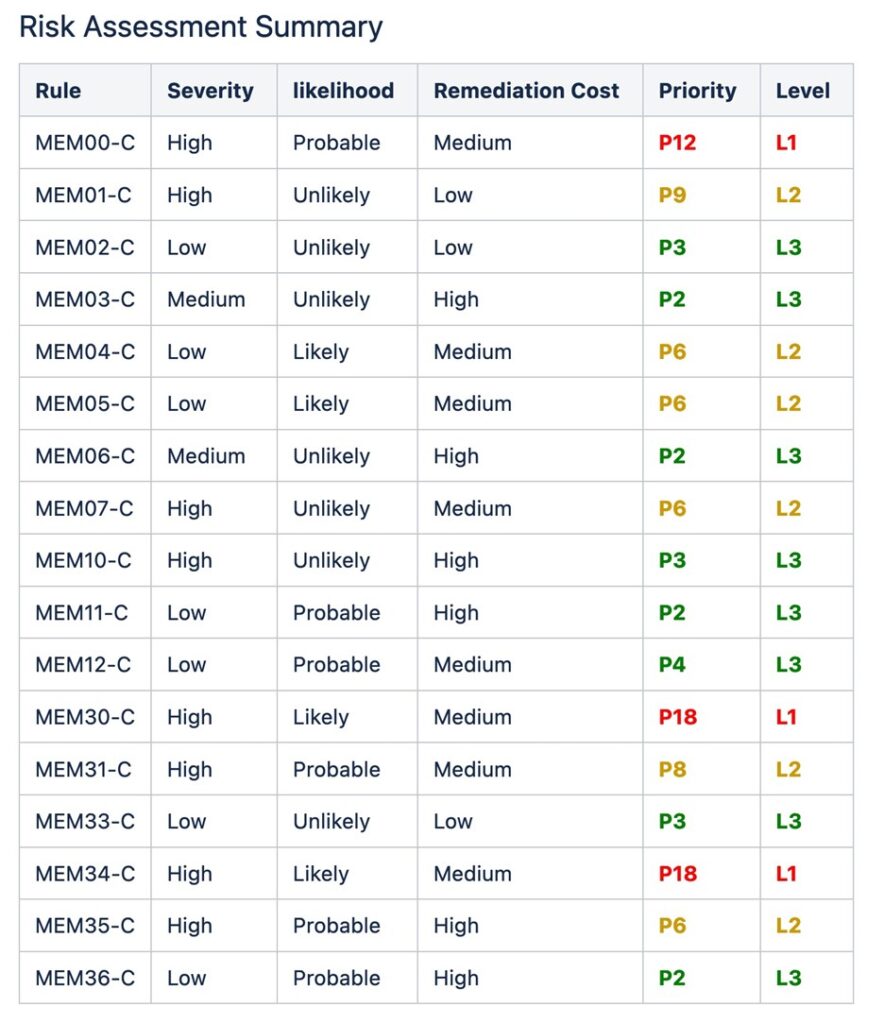
Una estrategia de prevención clave es adoptar un estándar de codificación adaptado de las pautas de la industria como SEI CERT y aplicarlo en la codificación futura. La prevención de estas vulnerabilidades con mejores prácticas de codificación es más barata, menos riesgosa y tiene el mayor retorno de la inversión.
La ejecución de un análisis estático del código recién creado es rápida y sencilla. Es fácil para los equipos integrar tanto en el IDE de escritorio como en el proceso de CI / CD. Para evitar que este código aparezca en la compilación, es una buena práctica investigar las advertencias de seguridad y las prácticas de codificación inseguras en esta etapa.
Una parte igualmente importante para detectar prácticas de codificación deficientes es la utilidad de los informes. Es importante comprender la causa raíz de las infracciones del análisis estático para solucionarlas de forma rápida y eficiente. Aquí es donde las herramientas comerciales como Parasoft Prueba C / C ++, puntoPRUEBAy jprueba brillo.
Las herramientas de prueba automatizadas de Parasoft brindan un seguimiento completo de las advertencias, las ilustran dentro del IDE y recopilan información de compilación y otra información de forma continua. Estos datos recopilados junto con los resultados de las pruebas y las métricas proporcionan una visión integral del cumplimiento con el estándar de codificación del equipo junto con el estado general de calidad y seguridad.
Los desarrolladores pueden filtrar aún más los hallazgos en función de otra información contextual, como los metadatos del proyecto, la antigüedad del código y el desarrollador o equipo responsable del código. Herramientas como Parasoft con inteligencia artificial (IA) y aprendizaje automático (ML) utilizan esta información para ayudar a determinar aún más los problemas más críticos.
Los cuadros de mando e informes incluyen los modelos de riesgo que forman parte de la información proporcionada por OWASP, CERT y CWE. De esa manera, los desarrolladores comprenden mejor el impacto de las vulnerabilidades potenciales informadas por la herramienta y cuáles de estas vulnerabilidades deben priorizar. Todos los datos generados a nivel de IDE están correlacionados con las actividades posteriores descritas anteriormente.
Conclusión: proteger su código contra desbordamientos de búfer
Los desbordamientos del búfer y otros errores de gestión de la memoria siguen afectando a las aplicaciones. Siguen siendo una de las principales causas de vulnerabilidades de seguridad. A pesar del conocimiento de cómo funciona y se explota, sigue siendo frecuente. Ver el Salón de la vergüenza de IoT para ejemplos recientes.
Proponemos un enfoque de prevención y detección para complementar las pruebas de seguridad activas que previenen los desbordamientos del búfer antes de que se escriban en el código lo antes posible en el SDLC. Prevenir dichos errores de administración de memoria en el IDE y detectarlos en el proceso de CI/CD es clave para eliminarlos de su software.
Los equipos de software inteligentes pueden minimizar los errores de gestión de la memoria. Pueden generar un impacto en la calidad y la seguridad con los procesos, las herramientas y la automatización adecuados en sus flujos de trabajo existentes.



