
Únase a nosotros el 30 de abril: Presentación de la prueba CT de Parasoft C/C++ para pruebas continuas y excelencia en el cumplimiento | Regístrese ahora
Saltar a la sección
Añadiendo vida a la virtualización del servicio: Pruebas de estado y de transición de estado
3 de agosto de 2023
8 min leer
Crear una representación virtual estable para lograr un comportamiento con estado de sus cargas de trabajo de desarrollo puede ser complicado. Así es como Parasoft Virtualize puede ayudarlo a simular y probar sus servicios virtuales.
Saltar a la sección
Saltar a la sección
En la virtualización de servicios, una parte crítica de crear servicios virtuales realistas es garantizar que el servicio tenga un comportamiento con estado para que pueda conservar su estado de ejecución de prueba a ejecución de prueba. Pero, ¿cuál es el límite? ¿Cuándo la simulación se convierte en demasiada simulación? Profundicemos en las pruebas de transición de estado y cómo saber cuándo las necesita.
Para acelerar las pruebas funcionales, es esencial tener acceso sin restricciones a un entorno de prueba confiable y realista. Un entorno de prueba completo incluye la aplicación bajo prueba (AUT) y todos sus componentes dependientes, como API, servicios de terceros, bases de datos, aplicaciones y otros puntos finales.
La virtualización de servicios permite a los equipos hacer lo siguiente, lo que en última instancia les permite realizar pruebas antes, más rápido y de forma más completa.
- Obtenga acceso al entorno de prueba completo que necesitan, incluidos todos los componentes críticos del sistema dependiente.
- Modifique el comportamiento de esos componentes dependientes de maneras que serían imposibles con un entorno de prueba por etapas.
Comportamiento con estado
Una parte fundamental de la creación de dependencias virtualizadas realistas es tener un comportamiento con estado. En otras palabras, una dependencia virtualizada puede conservar su estado de ejecución de prueba a ejecución de prueba. Considere un ejemplo de simulación de un componente de carrito de compras virtualizado. Una API simple permite buscar, agregar, recuperar y eliminar artículos del carrito.
Con el comportamiento sin estado, simular la búsqueda y el guardado de artículos en el carrito no cambiará el estado del carrito. La prueba de la secuencia de recuperación y eliminación de datos del carrito fallará porque el carrito permanecerá en su estado inicial (vacío), como se ilustra a continuación.
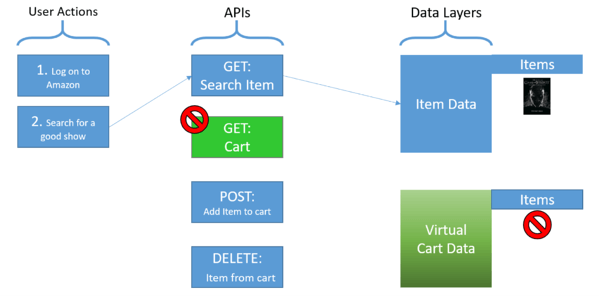
Sin embargo, si el carrito de compras virtual tiene un comportamiento con estado, donde su estado (vacío o con uno o más elementos) se conserva de una prueba a otra y también cambia según las entradas de la aplicación bajo prueba, puede comenzar a probar el proceso de manera significativa.
Usando pruebas con estado, el servicio virtualizado ahora puede cambiar el estado de vacío a "lleno con elemento agregado" y devolver la información adecuada. Si se agrega un artículo al carrito y el AUT consulta el carrito, se devuelven los datos apropiados. Es posible realizar una prueba más realista utilizando pruebas con estado, y consultar el carrito ahora devuelve el artículo agregado, como se muestra a continuación.
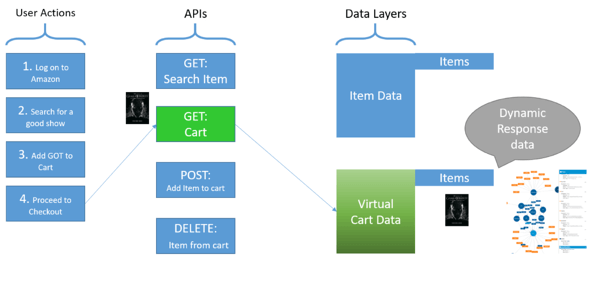
En resumen, para tener servicios virtuales confiables y reutilizables, es fundamental que puedan imitar el servicio real lo suficiente como para proporcionar un resultado significativo a la aplicación que se está probando, y esto puede requerir pruebas con estado.
Además del estado del propio servicio virtual, es posible que también deba simular cambios de estado en función de diferentes entradas potenciales, y esto se denomina prueba de transición de estado.
¿Qué son las pruebas de transición estatal?
Las transiciones de estado son el componente de acción de las máquinas de estados finitos, que se definen como:
“…una máquina abstracta que puede estar exactamente en uno de un número finito de estados en un momento dado. El FSM puede cambiar de un estado a otro en respuesta a algunas entradas externas; el cambio de un estado a otro se llama transición. Un FSM se define por una lista de sus estados, su estado inicial y las condiciones para cada transición”.
Las máquinas de estado son una forma útil de describir objetos y, a menudo, se usan explícitamente como modelo de programación. En otros casos de prueba, como nuestro carrito de compras, podría haber una máquina de estado implícita para describir su comportamiento. Considere la siguiente máquina de estado para el ejemplo anterior del carrito de compras.
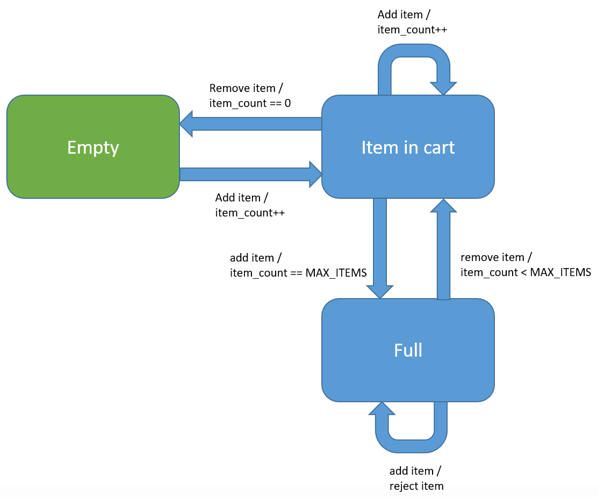
El estado inicial del carrito es vacío. A medida que se agregan artículos al carrito, el estado cambia de "Vacío" a "Artículo en el carrito". Las transiciones se inician en respuesta a eventos. En este caso, agregar o eliminar un artículo del carrito.
Las transiciones a menudo tienen condiciones antes de que se tomen, por ejemplo, la transición de regreso al estado Vacío solo ocurre cuando la cantidad de elementos vuelve a ser cero. Las transiciones a menudo realizan acciones, como incrementar el número de artículos en el carrito, en este ejemplo. Aunque es poco probable que el carrito esté programado como una máquina de estados, hay uno implícito que es útil para definir su comportamiento.
Considere otro ejemplo simple de un componente de inicio de sesión de usuario que bloquea a un usuario después de una cierta cantidad de reintentos:
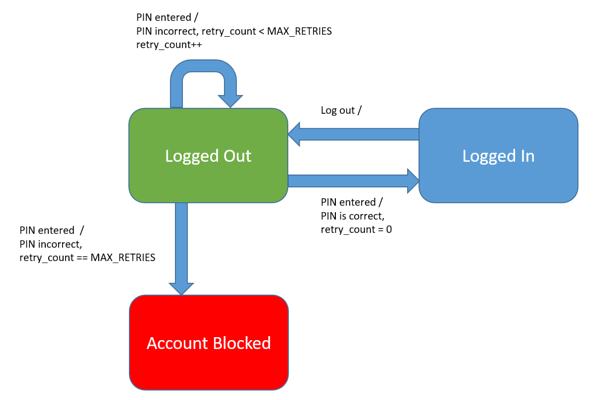
En el componente de inicio de sesión, el estado inicial es cerrar sesión. Un usuario solo puede iniciar sesión cuando se ingresa un PIN correcto. Después de un número definido de intentos de inicio de sesión (MAX_RETRIES), la cuenta se bloquea. En este caso de prueba, la cuenta bloqueada puede considerarse un estado final, ya que no hay forma de pasar de él.
Diagramas de transición de estado
Como se muestra en los dos ejemplos de transición anteriores, los diagramas de estado son representaciones gráficas de máquinas de estado finito. Modelan el comportamiento de un sistema o proceso que puede existir en diferentes estados y las transiciones entre esos estados en función de ciertos eventos o condiciones.
En un diagrama de estado, los estados se representan como cuadros redondeados y las transiciones entre estados son flechas. Cada estado representa una condición particular o modo del sistema. Las transiciones indican cómo el sistema puede pasar de un estado a otro y generalmente se etiquetan con el evento que provoca la transición.
Los eventos en las máquinas de estado pueden ser entradas externas, acciones internas o el paso del tiempo. Cuando ocurre un evento, el sistema sufre una transición y pasa a un nuevo estado.
Tablas de transición de estado
Las tablas de transición de estado son representaciones tabulares que se utilizan para describir el comportamiento de una máquina de estado de forma sistemática. La tabla define los estados posibles, los eventos de entrada y las transiciones de estado resultantes.
En una tabla de transición de estado, las filas representan estados y las columnas representan un evento o condición de entrada. Las celdas de la tabla especifican el estado resultante cuando ocurre un evento particular en un estado específico. Esto permite una representación concisa y estructurada de las transiciones de estado.
| Estado / Evento | PIN ingresado (comprobar PIN, PIN correcto) | PIN ingresado (PIN, PIN incorrecto, incremento de reintentos, reintentos>=MAX) | PIN ingresado (verificar PIN, PIN incorrecto, incrementar reintentos, reintentos | Cerrar Sesión |
|---|---|---|---|---|
| De Desconexión | Conectado | Cuenta bloqueada | De Desconexión | |
| Conectado | De Desconexión | |||
| Cuenta bloqueada |
Ventajas y desventajas de las pruebas de transición de estado
Las ventajas de utilizar pruebas de transición de estado incluyen las siguientes.
- Brinda una cobertura de prueba exhaustiva al examinar sistemáticamente todos los estados y transiciones posibles en la API, lo que garantiza una cobertura más completa del comportamiento de la API.
- A través de una mayor cobertura viene una mejor detección de errores y vulnerabilidades de seguridad.
- Se convierte en una forma más sucinta de expresar el comportamiento a medida que los evaluadores se familiarizan con él y simplifica las pruebas de API en general.
- Las pruebas reutilizables reducen el trabajo requerido para las pruebas de regresión.
Hay algunas desventajas en las pruebas de transición de estado. Lo primero y más importante es el nivel de esfuerzo requerido para representar una API compleja. Si la traducción de la Comportamiento de la API salidas en una máquina de estado compleja, será difícil de entender, usar y mantener. Además, las pruebas de transición de estado son sensibles a los cambios en la API: requieren un mantenimiento constante para mantenerse al día con estas actualizaciones.
¿Cuándo usar las pruebas de transición estatal?
La prueba de transición de estado tiene más sentido, como era de esperar, cuando la API tiene una naturaleza con estado, como mantener una sesión o contexto en varias solicitudes. Este tipo de prueba ayuda a verificar que la API administra y mantiene correctamente el estado a lo largo de la interacción, lo que garantiza un comportamiento uniforme en diferentes solicitudes y transiciones.
Las API pueden documentar su comportamiento en términos de estados y eventos, en cuyo caso la verificación puede tomar la misma forma. En otros casos, la API puede involucrar un proceso comercial complejo que tiene múltiples etapas en el flujo de trabajo. Las pruebas de transición de estado se pueden utilizar para probar mejor estos escenarios complejos.
Simulando estado con Parasoft Virtualize
Entonces, ¿cómo ayuda esto con las pruebas y los servicios virtuales? Bueno, es posible usar Virtualización de Parasoft para simular el comportamiento con estado de modo que los servicios devuelvan las respuestas adecuadas de una ejecución de prueba a otra, representando valores realistas esperados por AUT.
Los servicios virtualizados reaccionan a la entrada de las pruebas y conservan los valores según sea necesario, lo que amplía la utilidad de los datos de prueba capturados y simulados, que permanecen estáticos a menos que se mejoren con un comportamiento con estado. En Parasoft Virtualize, un servicio se virtualiza como CRUD (Crear, Leer, Actualizar, Eliminar) para indicar que su fuente de datos de prueba es persistente y se puede manipular según sea necesario durante la prueba. Vea la captura de pantalla a continuación.
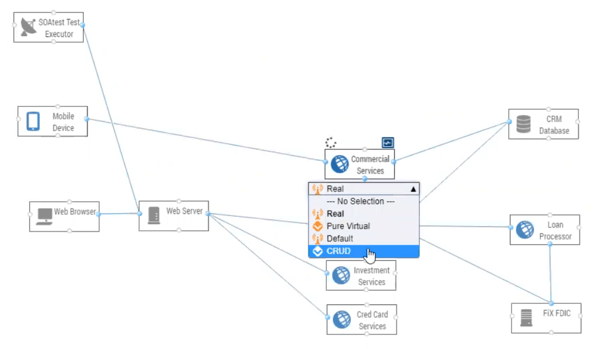
Parasoft Virtualize admite el comportamiento con estado en la fuente de datos de prueba o motor asociado con cada servicio virtual, que no solo almacena datos de prueba, sino que también proporciona la herramienta CRUD para manipular datos en función de la reacción a las solicitudes API recibidas. Estas actualizaciones de datos en la fuente de fecha de prueba se basan en eventos de entrada, como los que se analizaron anteriormente en los diagramas de transición de estado: llega el evento de entrada, se produce la transición de estado y se lleva a cabo la acción.
Para apoyar todo esto, el gestión de datos de prueba La herramienta en Parasoft Virtualize está configurada para realizar una actualización basada en una fuente de datos y un evento entrante.
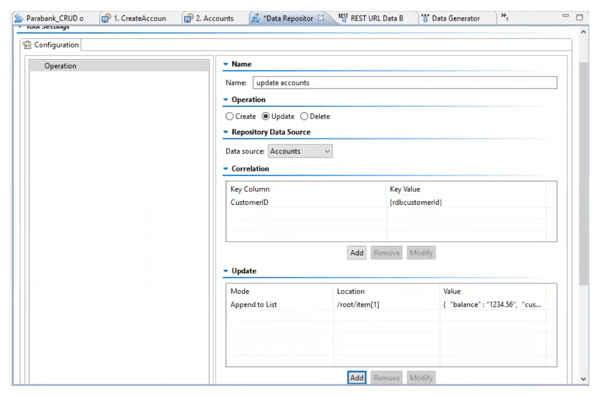
Las actualizaciones del origen de datos de prueba pueden ser elementos de datos individuales u objetos completos. La herramienta también le permite crear y eliminar registros según las reglas comerciales requeridas. De hecho, es lo suficientemente potente como para simular un comportamiento complejo, lo que plantea la pregunta: ¿cuándo es demasiada simulación, demasiada?
Los pros y los contras de la virtualización con estado
El uso de la virtualización pura es útil en las pruebas, ya que elimina la complejidad de tratar con un servicio real y aísla la aplicación que se está probando. Además, la eliminación de los servicios en vivo significa que las pruebas se pueden ejecutar en paralelo, en varios escritorios al mismo tiempo, sin afectar los sistemas de producción ni la necesidad de una copia dedicada del servicio. Pero un servidor virtual puro solo devuelve un reconocimiento como "sí, se llamó a esta API". En muchos casos, esto es suficiente, hasta que, por supuesto, no lo es. A medida que surgen casos de prueba más complejos, necesitamos que nuestros servidores virtualizados se vuelvan más inteligentes.
Usando el ejemplo del carrito de compras de arriba, es mucho más útil para su servicio de compras virtual no solo reconocer que los artículos se han agregado al carrito, sino también simular la adición de artículos al carrito. De esta manera, una consulta para determinar la cantidad de artículos en el carrito tendrá éxito con un valor correcto. También podríamos simular un estado de "carrito lleno" como se describe en la representación de la máquina de estado anterior. El comportamiento con estado es necesario para dar a nuestras pruebas resultados más significativos y aumentar la cobertura de los casos de prueba.
Pero llega un punto en el que simular la lógica empresarial se vuelve demasiado complejo. La intención de la virtualización es disminuir el trabajo y aumentar la productividad, por lo que hay rendimientos decrecientes en la simulación de la complejidad.
Es difícil decir el límite, pero si la complejidad va mucho más allá de nuestro carrito de compras o ejemplo de inicio de sesión, entonces se vuelve difícil justificar el esfuerzo. ¿Cómo puede estar seguro de que está simulando el comportamiento correcto? ¡No desea una situación en la que su aplicación esté diseñada para funcionar con un servicio simulado pero no funcione correctamente con el servicio real! Todavía se necesita el uso de servicios en vivo en la validación. Afortunadamente, Gerente de Medio Ambiente de Parasoft CTP El módulo facilita el cambio.
Resumen
El comportamiento con estado es una parte crítica de la creación de servicios virtualizados realistas, necesarios para ayudar a aislar las aplicaciones bajo prueba. Es necesario conservar el estado de los datos de prueba de una prueba a otra para obtener pruebas más realistas y útiles. Virtualización de Parasoft proporciona una solución integral de gestión de datos de prueba que da vida a los servicios virtualizados con respuestas con estado y basadas en el estado a las entradas de las llamadas a la API.
La simulación debe usarse con cautela, ya que simular una lógica comercial compleja tiene rendimientos decrecientes y el riesgo de alejarse demasiado de la realidad. Un uso inteligente de la simulación genera grandes beneficios de forma aislada, lo que a su vez desacopla las dependencias de los servidores activos. Sin embargo, dado que los servidores en vivo aún desempeñan un papel en la validación final, se requieren herramientas de virtualización de servicios como Parasoft Virtualize para admitir la combinación y combinación de estos entornos sin problemas.



