
Únase a nosotros el 30 de abril: Presentación de la prueba CT de Parasoft C/C++ para pruebas continuas y excelencia en el cumplimiento | Regístrese ahora
Saltar a la sección
Facilitar la gestión de datos de prueba (TDM) con la simulación de datos
8 de agosto de 2021
6 min leer
¿Alguna vez se preguntó cuál es la mejor manera de facilitar la gestión de datos de prueba (TDM) con la simulación de prueba? Vea cómo la solución de datos de prueba virtual de Parasoft puede ayudarlo a lograrlo.
Saltar a la sección
Saltar a la sección
Para habilitar las pruebas de integración paralelas que cambian las pruebas funcionales a la izquierda, las organizaciones pueden aprovechar el enfoque de Parasoft para gestión de datos de prueba (TDM) que utiliza inteligencia artificial, aprendizaje automático y datos de prueba virtuales para reemplazar la necesidad de puntos finales físicos y bases de datos. Exploremos cómo funciona.
El problema de los datos de prueba
La validación y verificación del software sigue siendo uno de los aspectos más costosos y que requieren más tiempo del desarrollo de software empresarial. La industria ha aceptado que las pruebas son difíciles, pero a menudo se pasan por alto las causas fundamentales. Adquirir, almacenar, mantener y usar datos de prueba para realizar pruebas es una tarea difícil que lleva demasiado tiempo.
A partir de los datos de la industria, vemos que hasta el 60% del tiempo de desarrollo y prueba de aplicaciones puede dedicarse a tareas relacionadas con los datos, de las cuales una gran parte es la gestión de datos de prueba. Los retrasos y los gastos presupuestarios son solo una parte del problema: la falta de datos de prueba también resulta en pruebas inadecuadas, que es un problema mucho mayor, lo que inevitablemente resulta en defectos que se introducen en la producción.
Seminario web: TDM para ganar: cómo la gestión de datos de prueba permite realizar pruebas continuas
Las soluciones tradicionales en el mercado para TDM no han mejorado con éxito el estado de los desafíos de los datos de prueba; echemos un vistazo a algunos de ellos.
Los 3 enfoques tradicionales para la gestión de datos de prueba
Los enfoques tradicionales se basan en hacer una copia de una base de datos de producción, o exactamente lo contrario, utilizando datos generados sintéticos. Hay 3 enfoques tradicionales principales.
1. Clone la base de datos de producción.
Los probadores pueden clonar la base de datos de producción para tener algo contra lo que probar. Dado que se trata de una copia de la base de datos de producción, la infraestructura necesaria también debe duplicarse. El cumplimiento de la seguridad y la privacidad requiere que cualquier información personal confidencial se guarde de cerca, por lo que a menudo se utiliza el enmascaramiento para ocultar estos datos.
2. Clone un subconjunto de la base de datos de producción.
Un subconjunto de la base de datos de producción es un clon parcial de la base de datos de producción, que solo incluye la parte necesaria para las pruebas. Este enfoque requiere menos hardware pero, al igual que el método anterior, también requiere enmascaramiento de datos e infraestructura similar a la base de datos de producción.
3. Genere / sintetice los datos.
Al sintetizar datos, no se depende de los datos del cliente, pero los datos generados son lo suficientemente realistas como para ser útiles para las pruebas. Sintetizar la complejidad de una base de datos de producción heredada es una gran tarea, pero elimina los desafíos de seguridad y privacidad que están presentes con los mecanismos de clonación.
Sea inteligente: utilice la simulación para acelerar las pruebas de API
Problemas con los enfoques tradicionales de TDM
Primero, consideremos el enfoque más simple (y sorprendentemente más común) para TDM empresarial y eso es clonar una base de datos de producción con o sin subconjuntos. ¿Por qué este enfoque es tan problemático?
- Costos y complejidad de la infraestructura. Probablemente la mayor caída de los enfoques TDM tradicionales, las bases de datos heredadas pueden residir en un mainframe o consistir en múltiples bases de datos físicas. Duplicar un solo sistema de producción para un equipo es una empresa costosa.
- Privacidad y seguridad de los datos. La privacidad y la seguridad son siempre una preocupación cuando se utilizan bases de datos de producción, y los entornos de prueba a menudo no cumplen con los controles de privacidad y seguridad necesarios. El enmascaramiento es la solución habitual para manejar estas inquietudes, alterando la información sensible para no revelar ninguna información de identificación personal, pero desafortunadamente, el enmascaramiento es casi imposible sin riesgo de filtrar información privada porque es posible anonimizar los datos de prueba, a pesar de los mejores esfuerzos del mejor equipo de prueba. Las empresas que necesitan cumplir con GDPR, por ejemplo, pueden tener dificultades para convencer a los reguladores de que su entorno de prueba clonado cumple con los controles de privacidad requeridos.
- Falta de paralelismo y colisiones de datos. Dados los costos de infraestructura, hay un conjunto limitado de bases de datos de prueba disponibles y la ejecución de múltiples pruebas en paralelo genera preocupaciones sobre los conflictos de datos. Las pruebas pueden eliminar o alterar registros en los que se basan otras pruebas, por ejemplo. Esta falta de paralelismo significa que las pruebas se vuelven menos eficientes y los evaluadores deben preocuparse por la integridad de los datos después de cada sesión de prueba.
- El subconjunto no ayuda mucho. Aunque podría ser posible crear un subconjunto manejable que requiera menos infraestructura, es un proceso complejo. Se debe mantener la integridad referencial y los problemas de privacidad y seguridad permanecen en los subconjuntos.
- Sintetizar datos cura las preocupaciones sobre la privacidad, pero requiere mucha experiencia en bases de datos y dominios. Crear y completar una versión realista de una base de datos de prueba requiere un conocimiento profundo de la base de datos existente y la capacidad de recrear una versión sintética con datos que sean adecuados para la prueba. Entonces, si bien este enfoque resuelve muchas de las preocupaciones de seguridad y privacidad, requiere mucho más tiempo de desarrollo para crear la base de datos. Los problemas de infraestructura persisten si la base de datos de prueba es grande y el paralelismo puede ser limitado dependiendo de cuántas bases de datos de prueba se puedan usar simultáneamente.
Solución de problemas de gestión de datos de prueba con simulación de datos
El enfoque simplificado y más seguro para gestión de datos de prueba que ofrecemos en Parasoft en nuestra Prueba SOA, Virtualizar, CTP Las herramientas de datos de prueba virtuales son mucho más seguras y resuelven estos problemas tradicionales. Entonces, ¿en qué se diferencia de los enfoques tradicionales?
Pruebe lo inintestable: Alaska Airlines resuelve el dilema del entorno de prueba
La diferencia clave es que recopila datos de prueba al capturar el tráfico de las llamadas a la API y las transacciones JDBC / SQL durante las pruebas y el uso normal de la aplicación. El enmascaramiento se realiza en los datos capturados según sea necesario, y los modelos de datos se generan y se muestran en la interfaz de administración de datos de prueba de Parasoft. Los metadatos y las restricciones de datos del modelo se pueden inferir y configurar dentro de la interfaz, y se pueden realizar operaciones adicionales de enmascaramiento, generación y subconjunto. Esto proporciona un portal de autoservicio donde Se pueden aprovisionar fácilmente varios conjuntos de datos desechables para brindar a los evaluadores total flexibilidad y control de sus datos de prueba, como puede ver en las capturas de pantalla a continuación:
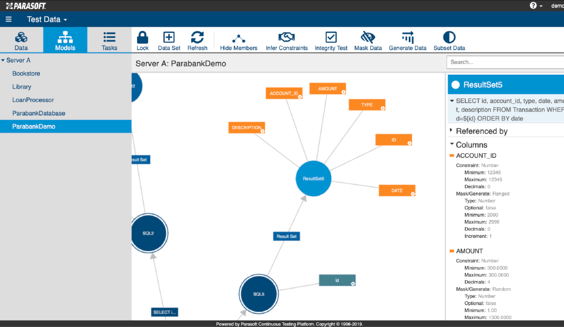
Parasoft's tecnología de gestión de datos de prueba virtual se complementa con la virtualización de servicios, donde las dependencias de back-end restringidas se pueden simular para desbloquear las actividades de prueba. Un buen ejemplo sería reemplazar la confianza en una base de datos física compartida intercambiándola con una base de datos virtualizada que simule las transacciones de JDBC/SQL, lo que permite realizar pruebas paralelas e independientes que, de lo contrario, entrarían en conflicto. El motor de administración de datos de prueba de Parasoft amplía el poder de la virtualización de servicios al permitir que los probadores generen, subconjunto, enmascaren y creen datos de prueba personalizados individuales para sus necesidades.
Al reemplazar las dependencias compartidas, como las bases de datos, la virtualización de servicios elimina la necesidad de la infraestructura y la complejidad necesarias para alojar el entorno de la base de datos. A su vez, esto significa conjuntos de pruebas aislados y la capacidad de cubrir casos extremos y de esquina. Aunque las dependencias virtualizadas no son "reales", las acciones con estado, como las operaciones de inserción y actualización en una base de datos, se pueden modelar dentro del activo virtual. Vea esto conceptualmente a continuación:
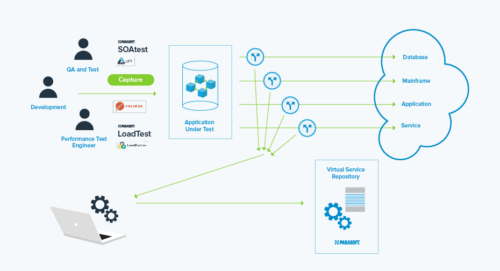
La ventaja clave de este enfoque es que evita las complejidades y los costos de infraestructura de la clonación de bases de datos, lo que permite Pruebas de nivel de API (como pruebas de integración) mucho antes que con otros métodos de datos de prueba.
Algunos otros beneficios de este enfoque incluyen:
- Debido a que no requiere una infraestructura de base de datos subyacente, generalmente puede ejecutarse localmente en las estaciones de trabajo de los desarrolladores y evaluadores.
- Los entornos de prueba aislados únicos para cada probador significan que no hay colisiones de datos ni preocupaciones sobre la integridad de los datos para una base de datos de prueba compartida. Las pruebas se vuelven muy paralelas, eliminando el tiempo de espera y los ciclos desperdiciados de los enfoques tradicionales.
- Los probadores pueden cubrir fácilmente casos de esquina que podrían causar corrupción y otros problemas en una base de datos de prueba. Dado que cada entorno de prueba está aislado, los probadores pueden realizar fácilmente pruebas destructivas, de rendimiento y de seguridad, sin preocuparse por la integridad de un recurso compartido.
- Es fácil compartir pruebas y datos entre el equipo para evitar la duplicación de esfuerzos, y las pruebas de API se pueden personalizar para otros fines, como pruebas de seguridad y rendimiento.
- El uso de servidores virtualizados elimina la complejidad del esquema de la base de datos subyacente. Prueba de estado está disponible para proporcionar escenarios realistas.
- Al capturar solo los datos que necesita con el enmascaramiento dinámico, ya no necesita una base de datos clonada, colocando el foco de las pruebas de integración en las API, en lugar de mantener una base de datos clonada compartida.
La prueba en la base de datos física seguirá siendo necesaria, pero solo se requerirá hacia el final del proceso de entrega del software cuando todo el sistema esté disponible. Este enfoque para probar los datos no elimina por completo la necesidad de realizar pruebas con la base de datos real, pero reduce la dependencia de la base de datos en las primeras etapas del proceso de desarrollo de software para acelerar las pruebas funcionales.
Resumen
Los enfoques tradicionales para probar la administración de datos para el software empresarial se basan en la clonación de bases de datos de producción y su infraestructura, cargados de costos, privacidad y preocupaciones de seguridad. Estos enfoques no son escalables y dan como resultado un desperdicio de recursos de prueba. Parasoft's solución de datos de prueba virtual vuelve a centrarse en las pruebas y la reconfiguración bajo demanda de los datos de prueba, lo que permite realizar pruebas de integración paralelas que salieron de esta etapa crítica de pruebas.
La solución a sus problemas de gestión de datos de prueba
Contenido recomendado

Publicación relacionada + Recursos

Calculadora de ROI

