
Únase a nosotros el 30 de abril: Presentación de la prueba CT de Parasoft C/C++ para pruebas continuas y excelencia en el cumplimiento | Regístrese ahora
Saltar a la sección
Riesgo y deuda de calidad: lo que no sabe puede perjudicarlo

Sábado, Junio 20, 2023
11 min leer
Muchas incógnitas en la ecuación de desarrollo se eliminan al saber dónde está el riesgo y cómo cada cambio de código afecta la seguridad de su sistema. Por lo tanto, la deuda de calidad y seguridad puede ser superada con el énfasis apropiado. Aprenda a priorizar y reducir efectivamente el riesgo asociado con las modificaciones del código.
Saltar a la sección
Saltar a la sección
Cuando se trata de evaluar el riesgo de una base de código, no se trata de un número mágico de una sola viñeta, sino de un simple semáforo de pasar/no pasar. El riesgo es multidimensional y multivariante. Se mide de manera diferente para diferentes organizaciones.
Probablemente ya sepa dónde están las partes malas o de alto riesgo del código. Son las partes del código que siempre cambian: pequeños ajustes aquí y allá para solucionar pequeños problemas que parecen inocuos en sí mismos, pero que normalmente representan la superposición de funciones sobre un diseño deficiente. Esta es la razón por la que realizar cambios en el código existente es la causa principal de la introducción de defectos en una aplicación.
Pero también sabemos que el cambio es constante. Nunca implementas todo completa o correctamente la primera vez. Además, a medida que los desarrolladores superponen el código existente, se pierde el conocimiento de cada caso de uso y escenario, aumenta la complejidad y el código se vuelve cada vez más riesgoso. Son estos cambios los que proporcionan la clave para aplicar el contexto al riesgo.
Tan importante como la visibilidad del riesgo en sí mismo es comprender cómo abordarlo. Cómo priorizar las acciones de remediación para lograr un nivel aceptable de riesgo mientras se minimiza el impacto en la velocidad del equipo. Esta publicación analiza solo eso: cómo evaluar el riesgo de los cambios de código y cómo priorizar y mitigar el riesgo de manera eficiente.
Descubriendo los costos ocultos de la deuda de calidad
La deuda de calidad, o deuda técnica, en el desarrollo de software puede imponer costos ocultos significativos en un proyecto. Si bien el impacto inmediato de tomar atajos o comprometer calidad del código puede parecer mínimo, las consecuencias a largo plazo pueden ser sustanciales. Estos son algunos de los costos ocultos asociados con la deuda de calidad.
Mayores costos de soporte y mantenimiento
Cuando tiene un código base que está mal diseñado, carece de la documentación adecuada o viola las mejores prácticas, se vuelve difícil de mantener con el tiempo. Los desarrolladores se esfuerzan más por comprender y navegar por el código base, lo que reduce la productividad y aumenta los costos de mantenimiento de los productos de software.
Cuanto más tiempo permanezca sin abordar la deuda de calidad, más productos o servicios serán propensos a defectos, fallos y fallas, lo que requerirá esfuerzos adicionales de soporte y mantenimiento. Esto no solo agota los recursos de los equipos de atención al cliente, sino que también exige una importante asignación de tiempo y dinero para solucionar los problemas. Estos costos continuos erosionan la rentabilidad y desvían recursos de otras iniciativas comerciales críticas.
Frustración y agotamiento de los empleados
La necesidad repetida de solucionar los problemas causados por la deuda técnica puede generar frustración, reducción de la productividad y agotamiento entre los miembros del equipo. Imagine someter a un equipo de desarrolladores a depurar o aplicar correcciones en un producto repetidamente. Si no es una brecha de seguridad hoy, son fallas totales en el tiempo de actividad, y la lista continúa. Tener desarrolladores en este tipo de ciclo puede desencadenar un éxodo masivo de una organización, lo que afecta la estabilidad y la experiencia de la fuerza laboral.
Acumulación de errores y defectos
El código de baja calidad es más propenso a errores y defectos. Cuando se toman atajos o se omiten pruebas exhaustivas, los errores pueden pasar desapercibidos y acumularse con el tiempo. Identificar y corregir estos atrasos de deudas técnicas se vuelve cada vez más difícil, lo que resulta en un mayor tiempo de depuración.
El costo de abordar estos errores y defectos en el futuro puede superar con creces el tiempo inicial ahorrado al tomar atajos. Además, la acumulación de errores y defectos también provoca retrasos en la entrega de productos y afecta la agilidad del equipo. Este suele ser el caso cuando el código base se ha hecho más complejo con ajustes sencillos aquí y allá.
Disminución de la satisfacción del cliente e innovación obstaculizada
La deuda de calidad puede afectar negativamente la experiencia del usuario final. Los usuarios pueden encontrar errores más frecuentes, experimentar un rendimiento más lento o enfrentar problemas de usabilidad. Esto puede resultar en la insatisfacción del cliente, críticas negativas y la posible pérdida de negocios. Además de afectar la satisfacción del cliente, la deuda de calidad acumulada limita la capacidad del software para adaptarse y evolucionar.
Agregar nuevas funciones o integrarse con otros sistemas se convierte en un desafío, lo que dificulta la innovación y la escalabilidad. Cuando las empresas tienen problemas de deuda de calidad, también puede disuadir a los desarrolladores de sugerir mejoras o introducir ideas innovadoras, ya que están agobiados por los problemas existentes.
Cumplimiento normativo y consecuencias legales
En ciertas industrias, la deuda de calidad puede resultar en el incumplimiento de los estándares regulatorios, lo que genera consecuencias legales y posibles sanciones financieras. El incumplimiento de las normas de calidad y seguridad puede dañar la reputación de la marca y erosionar la confianza del cliente, lo que exacerba aún más los costos ocultos.
Determinación del riesgo multivariante
El riesgo no es un solo número o un semáforo a nivel de proyecto. Pero, como se muestra en el gráfico circular a continuación, Parasoft usa colores de semáforo fácilmente asociados en la interfaz de usuario como una categorización del código base y una guía sobre dónde existen problemas reales y potenciales.
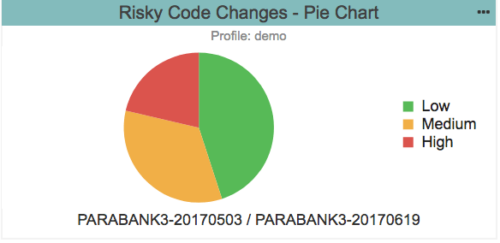
La categorización del riesgo es a la vez multidimensional y multivariante, reuniendo métricas de calidad a partir de técnicas de prueba de software como análisis estático y cobertura de código. Ninguna técnica única proporciona el valor de una dimensión específica, sino que proporciona un valor para una fórmula. Por ejemplo, la cobertura de código no es un buen número para usar solo porque podría tener una cobertura del 100% pero solo una pequeña cantidad de pruebas que hagan algo significativo. En su lugar, piense en lo que está utilizando la cobertura de código para decirle, como preguntar, ¿qué tan bien se prueba mi código? Luego, aumente eso con más datos para obtener un análisis más significativo.
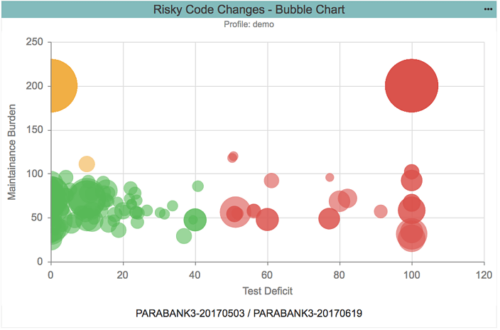
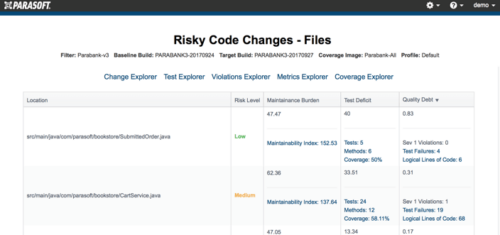
El gráfico de burbujas anterior ilustra la categorización del riesgo en función de dos dimensiones. Esto también se muestra en la siguiente captura de pantalla.
- Carga de mantenimiento. Combina el volumen de Halstead y la complejidad ciclomática estricta, el número de líneas de código y la proporción de código a comentarios para cuantificar qué tan mantenible y comprensible es el código.
- Déficit de prueba. Utiliza la cantidad de pruebas, la cantidad de métodos y la cobertura del código para cuantificar qué tan bien se ha probado el código.
El código que se ha probado de manera deficiente tiene un mayor déficit de prueba y se clasifica como de alto riesgo (rojo). El código que está bien probado y bien construido tiene una menor carga de mantenimiento y se clasifica como de bajo riesgo (verde).
Bases de código volátiles, donde cada cambio es un riesgo
Durante el calor del desarrollo, su base de código está en un estado de flujo constante y cada línea de cambio de código presenta un riesgo desconocido. ¿Romperá una característica fundamental? ¿Introduce un fallo de seguridad? Cuanta menos información, mayor es el riesgo. La cobertura de código debe usarse de manera inteligente para predecir dónde enfocar los recursos de prueba. Sin embargo, incluso con una mayor cobertura y pruebas, aún existe un riesgo adicional que se acumula con el tiempo.
El cambio en el código base nos brinda la tercera y más importante dimensión de riesgo: el tiempo. No el tiempo en el sentido tradicional, sino el tiempo en relación con las construcciones y los cambios entre ellas. Centrarse en las partes de la base de código que han cambiado entre compilaciones brinda la capacidad de concentrarse en abordar el código que es tanto el de mayor riesgo como el más relevante a medida que el equipo trabaja en esta parte de la base de código.
¿Lo está ralentizando la carga de la deuda de calidad?
El código reutilizado y heredado tiene su propia carga, especialmente en lo que respecta a la seguridad. Cada línea de código enviada o modificada se suma a esta deuda si no hay controles adecuados para mantener o mejorar la línea de base de calidad. Salir de esta deuda, como cualquier deuda, requiere enfoque y un compromiso de reducción. Además, como cualquier deuda, ¿cómo sabe uno dónde hacer recortes para ahorrar a menos que sepa dónde se gasta el dinero?
Una vez que identifique el código con el mayor riesgo y la mayor prioridad, considere la cantidad de trabajo necesario para mitigar el riesgo. Esta es la cuarta y última dimensión: deuda de calidad. En el gráfico de burbujas anterior, la deuda de calidad está representada por el tamaño de la burbuja: cuanto más grande es la burbuja, más problemas conocidos deben abordarse. En nuestro ejemplo, la deuda de calidad es una combinación de infracciones de análisis estático de alta gravedad (incluidas infracciones de umbrales establecidos para métricas de código) y fallas de prueba normalizadas por la cantidad de líneas lógicas de código.
¡Pero no es así como mido los riesgos!
No todas las organizaciones seguirán las mismas prácticas de calidad o acordarán qué factores tomar en consideración al calcular las dimensiones. Debe poder configurar y crear su propia definición de riesgo.
El ejemplo de este blog está disponible para los usuarios en la Mercado de Parasoft, lo que le permite utilizarlo de forma inmediata, ampliando y modificando para satisfacer sus necesidades específicas. Comenzando con el ejemplo, puede personalizar el análisis estático, los umbrales de métricas y las categorizaciones de riesgo para adaptarse a su organización.
Estrategias para hacer frente a la deuda de calidad
Es importante que los equipos de desarrollo administren y reduzcan la deuda de calidad a lo largo del tiempo para mantener la calidad del software, garantizar procesos de desarrollo eficientes y minimizar los costos a largo plazo. Para abordar de manera efectiva la deuda de calidad, es crucial adoptar estrategias que aborden su prevención, reducción y mejora continua. A continuación se muestra un desglose de algunas estrategias que las organizaciones pueden adoptar para hacer frente a la deuda de calidad.
Prevenga la deuda de calidad
La prevención de la deuda de calidad es un enfoque proactivo que se centra en evitar la acumulación de deuda técnica en primer lugar. Al adoptar las siguientes prácticas, los equipos de desarrollo de software pueden reducir la probabilidad de incurrir en una deuda de calidad significativa.
- Análisis de requisitos robusto. Invierta tiempo y esfuerzo por adelantado para comprender a fondo los requisitos del proyecto, las limitaciones y las expectativas de las partes interesadas. Definir claramente el alcance, la funcionalidad y los objetivos de rendimiento ayuda a sentar una base sólida para el desarrollo.
- Prácticas ágiles de desarrollo. Las metodologías ágiles promueven el desarrollo iterativo y enfatizan los bucles de retroalimentación continuos. Este enfoque permite la identificación temprana y la resolución de problemas de calidad, evitando que se conviertan en una deuda técnica significativa.
- Revisiones de código y programación en pareja. Fomentar una cultura de revisiones de código y programación en pareja dentro de los equipos de desarrollo. La revisión periódica del código y la colaboración en las tareas de desarrollo mejora la calidad del código, reduce la probabilidad de introducir deuda técnica y promueve el intercambio de conocimientos.
- Estándares de codificación consistentes. Establezca y haga cumplir los estándares de codificación para garantizar la uniformidad y la capacidad de mantenimiento de la base de código. Esto incluye pautas para convenciones de nomenclatura, formato de código y prácticas de documentación. Análisis de código automatizado Las herramientas proporcionadas por Parasoft pueden ayudar a hacer cumplir estos estándares.
Priorizar la reducción de la deuda de calidad
Abordar la deuda técnica requiere un enfoque proactivo y sistemático. Si bien puede ser tentador priorizar el desarrollo de nuevas funciones sobre la reducción de la deuda, descuidar la deuda técnica puede tener graves consecuencias. Aquí hay algunas estrategias para priorizar y reducir la deuda técnica de manera efectiva.
- Identificar y evaluar. El primer paso para priorizar la reducción de la deuda de calidad es identificar y evaluar las áreas de preocupación dentro de su proyecto de software. Realice revisiones periódicas de código, analice informes de errores y recopile comentarios de desarrolladores y usuarios. Buscar el código huele, puntos críticos de complejidad y áreas donde el sistema es propenso a fallas o cuellos de botella en el rendimiento. Evaluar el impacto y los riesgos potenciales asociados con cada elemento de deuda técnica. Al comprender el panorama de la deuda, el equipo puede tomar decisiones informadas sobre dónde concentrar los esfuerzos.
- Priorizar No todas las deudas técnicas tendrán el mismo impacto en el resultado o desempeño general de su proyecto de software. Es esencial priorizar la deuda en función de su posible impacto, gravedad y urgencia. Empiece por considerar las áreas que afectan significativamente la calidad del código, la estabilidad del sistema y la experiencia del usuario. Por ejemplo, si hay errores críticos que afectan la funcionalidad central, es crucial abordarlos primero. Además, también es esencial comprometerse con las partes interesadas clave para alinear las prioridades con los objetivos comerciales. Su aporte puede ayudar a determinar qué elementos de la deuda tienen el impacto más significativo en los clientes, los ingresos o el éxito general del proyecto.
- Probar y automatizar. Invertir en pruebas automatizadas es crucial para una reducción efectiva de la deuda. La implementación de un conjunto sólido de pruebas ayuda a detectar regresiones y garantiza la calidad del código a lo largo del tiempo. La integración de pruebas unitarias automatizadas, pruebas de integración y pruebas de aceptación en su proceso de desarrollo contribuye a la reducción de la deuda técnica.
Considere la posibilidad de implementar una canalización de integración y entrega continuas (CI/CD) que automatice los controles de calidad del código, las pruebas y los procesos de implementación. Esto garantiza que cada cambio realizado en el código base se pruebe exhaustivamente antes de implementarse, lo que evita la acumulación de nuevas deudas. Las soluciones de pruebas automatizadas agilizan significativamente el proceso de desarrollo e implementación, lo que le permite centrarse más en la reducción de la deuda y menos en las pruebas manuales y las tareas propensas a errores.
- Planificar mejoras incrementales. La reducción de la deuda técnica debe abordarse de forma incremental. Tratar de abordar todas las deudas a la vez puede ser abrumador y contraproducente. En su lugar, divida los elementos de deuda más grandes en tareas manejables y planifíquelas de forma incremental. Cree una hoja de ruta que describa las tareas específicas de reducción de la deuda que se abordarán en cada ciclo de desarrollo o sprint. Equilibre la reducción de la deuda con el desarrollo de nuevas funciones, asignando tiempo y recursos en consecuencia. Al tomar pasos pequeños y manejables, puede reducir la deuda de manera constante y al mismo tiempo brindar valor a los usuarios.
Código de refactorización continuamente
La refactorización de código es una técnica disciplinada que mejora la estructura interna y el diseño del código base sin cambiar su comportamiento externo. La refactorización continua del código es una práctica esencial para hacer frente a la deuda de calidad, ya que ayuda a mantener la calidad del código, reducir la complejidad y mejorar la capacidad de mantenimiento. Estas son algunas consideraciones clave para una refactorización de código eficaz.
- Refactorizar como práctica habitual. Integre la refactorización de código como parte integral del ciclo de desarrollo. Anime a los desarrolladores a refactorizar el código durante las etapas de desarrollo de características, corrección de errores y revisión de código para abordar la deuda técnica de forma incremental.
- Refactorización basada en pruebas. Adopte un enfoque de desarrollo basado en pruebas (TDD) donde las pruebas automatizadas se escriben primero antes de la refactorización. Esto garantiza que los cambios realizados durante la refactorización no introduzcan nuevos errores o regresiones. Las pruebas existentes sirven como una red de seguridad, brindando la confianza de que el código se comporta como se espera después de la refactorización.
- Herramientas de refactorización y compatibilidad con IDE. Utilice herramientas de refactorización y entornos de desarrollo integrados (IDE) que ofrecen capacidades de refactorización automatizadas. Estas herramientas pueden simplificar y acelerar el proceso de refactorización, reduciendo el esfuerzo requerido para una reducción de deuda de calidad.
- Supervise y mida los esfuerzos de refactorización. Realice un seguimiento de las actividades de refactorización que realiza y su impacto en la calidad y el mantenimiento del código. Las métricas como la complejidad del código, la cobertura del código y las tasas de errores pueden ayudar a evaluar la eficacia de los esfuerzos de refactorización.
Optimice los procedimientos de prueba y la documentación
Los procedimientos de prueba y la documentación efectivos juegan un papel crucial para minimizar la deuda de calidad y garantizar la confiabilidad del software. Su organización puede abordar la deuda de calidad optimizando los procedimientos de prueba y la documentación a través de las siguientes estrategias.
- Definir y estandarizar los procesos de prueba. Establezca procedimientos de prueba claros y bien definidos que cubran diferentes tipos de pruebas, incluidas las pruebas funcionales, de integración, de rendimiento y de seguridad. Estandarice estos procesos entre equipos y proyectos para garantizar la coherencia y reducir el riesgo de pasar por alto actividades de prueba críticas.
- Priorizar la cobertura de la prueba. Analice la aplicación o el producto bajo prueba para identificar áreas críticas que requieren pruebas exhaustivas. Priorice la cobertura de pruebas en estas áreas de alto riesgo para minimizar las posibilidades de que los defectos pasen desapercibidos. Utilice técnicas como las pruebas basadas en riesgos para asignar los recursos de prueba de manera eficaz y centrar los esfuerzos donde más se necesitan.
- Documentar los procedimientos de prueba. Cree documentación completa y actualizada que describa los procesos de prueba, los casos de prueba y los requisitos de datos de prueba. Haga que la documentación sea fácilmente accesible para todo el equipo para garantizar prácticas de prueba consistentes. Esta documentación también debe incluir pautas para escribir casos de prueba efectivos y pasos para reproducir problemas informados.
- Fomentar la colaboración entre los equipos de desarrollo y testing. Fomentar una estrecha colaboración entre los equipos de desarrollo y pruebas para fomentar una comprensión compartida de las metas y objetivos de calidad. Establezca canales de comunicación efectivos y fomente la retroalimentación periódica y el intercambio de conocimientos. La colaboración ayuda a cerrar la brecha entre el desarrollo y las pruebas, lo que lleva a una mejor cobertura de las pruebas, una resolución de errores más rápida y una deuda de calidad reducida.
Beneficios de abordar la deuda de calidad
Abordar la deuda de calidad es crucial para el éxito a largo plazo de los proyectos de software. Aquí hay algunas razones clave por las que debe comenzar a abordar la deuda de calidad en su empresa.
Satisfacción y retención del cliente
Cuando las empresas abordan la deuda de calidad, pueden mejorar significativamente la satisfacción del cliente. Al invertir en la calidad del software, pueden ofrecer un producto que funcione mejor, tenga menos errores y ofrezca una experiencia de usuario más fluida. Los usuarios apreciarán la mayor confiabilidad y estabilidad del software, lo que se traduce en mayores niveles de satisfacción y críticas positivas del público. Es más probable que los clientes satisfechos continúen usando el software, renueven licencias o suscripciones y se conviertan en defensores al recomendarlo a otros.
Ventaja Competitiva
En un mercado competitivo, abordar la deuda de calidad otorga a las empresas de desarrollo de software una clara ventaja sobre sus rivales. Al centrarse en la calidad del software, las empresas pueden ofrecer un producto que se destaque de la competencia. El software con menos problemas y mejor rendimiento puede atraer a nuevos clientes que valoran la confiabilidad y la eficiencia. También puede ayudar a retener a los clientes existentes que pueden estar considerando alternativas. Al enfatizar la calidad, las empresas pueden diferenciarse en el mercado y posicionar su software como una opción preferida.
Costos de mantenimiento reducidos
Uno de los inconvenientes significativos de la deuda de calidad es su impacto en los costos de mantenimiento. El software de mala calidad a menudo requiere correcciones de errores, parches y actualizaciones frecuentes, lo que puede llevar mucho tiempo y ser costoso. Al abordar la deuda de calidad de manera proactiva, las empresas pueden minimizar la necesidad de mantenimiento continuo, lo que produce una base de código de mayor calidad, reduce la aparición de errores y mejora la estabilidad general del software. Esto, a su vez, conduce a menores esfuerzos y costos de mantenimiento, lo que permite a las empresas asignar sus recursos de manera más eficiente al desarrollo de nuevas funciones, la innovación y otras prioridades comerciales.
Proceso de desarrollo eficiente
La deuda de calidad acumulada puede obstaculizar el proceso de desarrollo de varias formas. Puede causar retrasos, aumentar el tiempo dedicado a la depuración y crear complejidades técnicas que ralentizan el progreso. Al abordar la deuda de calidad, las empresas pueden optimizar su proceso de desarrollo. Los desarrolladores pueden trabajar con un código más limpio que es más fácil de entender y mantener. Esto da como resultado una mayor productividad, ya que dedican menos tiempo a la resolución de problemas y más tiempo a la creación de nuevas características y funciones. El proceso simplificado ayuda a los equipos a cumplir con los plazos, entregar el software a tiempo e iterar más rápido según los comentarios de los usuarios.
Escalabilidad a largo plazo
Descuidar la deuda de calidad puede impedir la escalabilidad de un producto de software. A medida que el software evoluciona y se agregan nuevas funciones, el código subyacente de baja calidad puede convertirse en una barrera importante para el crecimiento. Al abordar la deuda de calidad, las empresas se aseguran de que su software tenga una base sólida para la escalabilidad a largo plazo. Pueden refactorizar y optimizar el código base, haciéndolo más flexible y adaptable a las cambiantes necesidades comerciales y los avances tecnológicos. Esto permite que el mantenimiento, la extensión y la integración de nuevas funcionalidades sean más sencillos, lo que permite que el software escale de manera efectiva a medida que la empresa se expande o los requisitos de los usuarios evolucionan.
Conclusión
Equilibrar los presupuestos, los cronogramas y los objetivos de calidad con las medidas de seguridad adecuadas mientras se satisface a los clientes es una tarea difícil con riesgos en todo momento. Sin embargo, la automatización de las prácticas de calidad y la inteligencia de procesos ayudan a guiar dónde gastar mejor los recursos. Comprender dónde radica el riesgo y cómo cada cambio de código afecta la calidad y la seguridad de la línea de base reduce muchas incógnitas en la ecuación de desarrollo. Los equipos de desarrollo pueden vencer la deuda de calidad y seguridad con el enfoque correcto.



